
C语言安全
凭借良好的移植性和跨平台支持,以及高效率的低级处理能力,C语言成为现代最流行的操作系统平台的基石,也成为教育、研究和软件开发中最受欢迎的语言之一。
C语言灵活的类型转换和贴近底层机器实现、目标代码效率高的特性,一直是系统软件开发人员最为喜爱的。
随着软件系统的复杂度的不断提高,编码中的一些小瑕疵也越来越容易暴露出来,从而引发严重的安全问题,加之UNIX、Windows等主流操作系统的各种组件大多以C语言编写,黑客们乐此不疲地寻找着这方面的漏洞,这给全球的计算机系统带来了严重的威胁。
C语言安全需要注意哪些方面 ★
- 提高任何c或C++应用程序的整体安全性
- 阻止利用不安全的字符串操作逻辑进行缓冲区溢出、栈溢出以及面向返回值的编程攻击
- 避免因不正确使用动态内存管理函数而导致的漏洞和安全缺陷
- 消除因有符号整数溢岀、无符号整数回绕和截断误差而导致的整数相关问题
- 执行安全的I/O操作,避免文件系统漏洞
- 正确使用格式化输出函数,避免引入格式字符串漏洞
- 在开发并发代码时,避免竞争条件和其他可利用的漏洞
C语言安全的99条规则
每条规则和建议都有唯一的标识符,由3部分组成:
- 3个字母的助记符,代表在标准中所属的部分
- 2位数字,范围为00—99,数字00-29为建议保留,30-99为规则保留
- 大写字母C,表示这是一条C语言指导方针
规则的优先级
严重性:忽略规则的后果有多严重?
可能性:忽略规则引起的缺陷导致可利用漏洞的可能性有多大?
补救代价:使代码遵循规则的代价有多高?
每条规则的3个值相乘形成一个指标,用于确定应用规则的优先级。
不要对null指针进行解引用
EXP34-C,高,很可能,中,P18,L1,不要对null指针进行解引用。
在许多平台上,解引用null指针会造成异常程序终止。
不相容代码
#include /* From libpng */
#include
void func(png_structp png_ptr,int length,const void *user_data){
png_charp chunkdata;
chunkdata = (png_charp)png_malloc(png_ptr,length+1);
/*...*/
memcpy(chunkdata,user_data,length);
}
如果length的值为-1,加法的得数为0,png_malloc()将返回一个Null指针,赋给chunkdata。
之后,chunkdata指针作为memcpy()调用的目标参数,导致用户定义的数据覆盖地址0开始的内存。
在ARM和XScale架构中,0x0地址映射到内存中作为异常向量表;因此,解引用0x0不会导致程序终止。
相容代码
相容解决方案确保png_malloc()返回的指针不为null。它还使无符号类型size_t传递length参数,确保不会向func()传递负值。
#include /* From libpng */
#include
void func(png_structp png_ptr,size_t length,const void *user_data){
png_charp chunkdata;
if(length == SIZE_MAX){
/* Handl error */
}
chunkdata = (png_charp)png_malloc(png_ptr,length+1);
if(NULL == chunkdata){
/* Handl error */
}
/*...*/
memcpy(chunkdata,user_data,length);
/*...*/
}
缓冲区溢出 ★
STR31-C,高,很可能,中,P18,L1,保证字符串存储有足够的空间容纳字符数据和null结束符。
缓冲区溢出的概念 ★
将数据复制到不足以容纳数据的缓冲区,会导致缓冲区溢出。缓冲区溢出经常发生在字符串操作中。为了避免这种错误,可以截断限制拷贝,最好确保目标区域的大小足以容纳复制数据和null结束符。
产生缓冲区溢出的原因 ★
当向为某特定数据结构分配的内存空间的边界之外写入数据时,即会发生缓冲区溢岀。C和C++都容易发生缓冲区溢出问题,因为这两种语言具有以下共同之处。
- 将字符串定义为以空字符结尾的字符数组
- 未进行隐式的边界检査
- 提供了未强制性边界检查的标准字符串函数调用
取决于内存的位置以及溢出的规模,缓冲区溢出可能不会被侦测到,但它可能会破坏数据,导致程序岀现奇怪的行为甚至非正常中止。
并非所有的缓冲区溢岀都会造成软件漏洞。然而,如果攻击者能够操纵用户控制的输入来利用安全缺陷,那么缓冲区溢出就会导致漏洞了。例如,有一些广为人知的技术可以用于覆写栈帧以执行任意的代码。缓冲区溢出也可以在堆或静态内存区域被利用,它的做法是通 过覆写邻接内存的数据结构。
缓冲区溢出实例
不相容代码
下面代码中的循环将数据从src复制到dest。但是,因为循环没有考虑null结束符,它可能错误地写入dest结束位置之后的一个字节。
相容代码
字符串数据类型
在软件工程中,字符串是一个基本的概念,但它并不是C或C++的内置类型。标准C语言库支持的类型为char的字符串和类型为wchar_t的宽字符串。
字符串由一个以第一个空(null)字符作为结束的连续字符序列组成,并包含此空字符。一个指向字符串的指针实际上指向该字符串的起始字符。字符串长度指空字符之前的字节数,字符串的值则是它所包含的按顺序排列的字符值的序列。
数组大小
数组带来的问题之一是确定其元素数量。
void clear(int array[]) {
for (size_t i = 0; i < sizeof(array) / sizeof(array[0]): ++i){
array[i] = 0;
}
}
void dowork(void) {
int dis[12];
clear(dis):
/*...*/
}
这是因为sizeof运算符在应用于声明为数组或函数类型的参数时,它产生调整后的(即指针)类型大小。strlen()函数可以用来确定一个正确地以空字符结尾的字符串的长度,但不能用来确定一个数组的可用空间。
字符串初始化
数组变量常常由一个字符串字面值进行初始化,并且声明为一个与字符串字面值中的字 符数目相匹配的显式界限。例如,下面的声明使用一个字符串字面值初始化了一个字符数组,此字面值比数组能容纳的字符多一个字符(包括终结符'\0'):
const char s[3] = "abc";
虽然字符串字面值的大小是4,但数组s的大小是3,因此,尾随的空字节被删除。任何随后将数组作为一个空字节结尾的字符串的使用都会导致漏洞,因为s没有正确地以空字符'\0'结尾。
字符集
一个字符串中的字符都属于在执行环境中解释的字符集——执行字符集。这些字符由C标准定义的一个基本字符集和一组零个或多个扩展字符(它们不是基本字符集的成员)组成。 执行字符集的成员的值是具体实现定义的,但可能(例如)是美国7位ASCII字符集的值。
基本执行字符集/单字节字符集
基本执行字符集包括拉丁字母表的26个大写字母和26个小写字母、10个十进制数字、 29个图形字符、空格字符,以及表示水平制表符、垂直制表符、换页符、警告、退格键、回车和换行符的控制字符。
基本字符集的每个成员都适合用单个字节表示。
基本执行字符集中必须存在一个字节的所有位都设置为0的字符,称为空字符(null),它是用来终止字符串的。
宽字节字符集
若要处理大字符集的字符,程序可以将每个字符都表示为一个宽字符,宽字符一般比一个普通字符需要更多的空间。大多数实现选择16位或32位来表示一个宽字符。
一个宽字符串是一个连续的宽字符序列,它包括并由第一个null宽字符终止。一个指向宽字符串的指针指向其初始(最低地址的)宽字符。一个宽字符串的长度是null宽字符之前的宽字符的数量,而一个宽字符串的值是其所包含的宽字符的码值按顺序排列的序列。
多字节字符集
执行字符集可能包含大量的字符,因此需要多个字节来表示扩展字符集中的一些单个字符。这就是所谓的多字节(multibyte)字符集。在这种情况下,基本字符仍然必须存在,并且基本字符集的每个字符都编码为单字节。任何额外字符的存在、含义和表示都是特定于语言 环境的。一个字符申,可能有时会称为一个多字节字符串,以强调它可能会存在多字节字符。 这些与宽字符串不同,因为在宽字符串中每个字符都具有相同的长度。
WINDOWS字符转换接口API
MultiByteToWideChar:非Unicode转换成Unicode编码格式
WideCharToMultiByte:由Unicode转换为非Unicode编码格式
语言环境
C使用一个语言环境(locale)的概念,它可以由setlocale()函数改变,用来跟踪各种约定,如具体实现支持的语言和标点符号。当前语言环境确定哪些字符可用作可扩展字符。
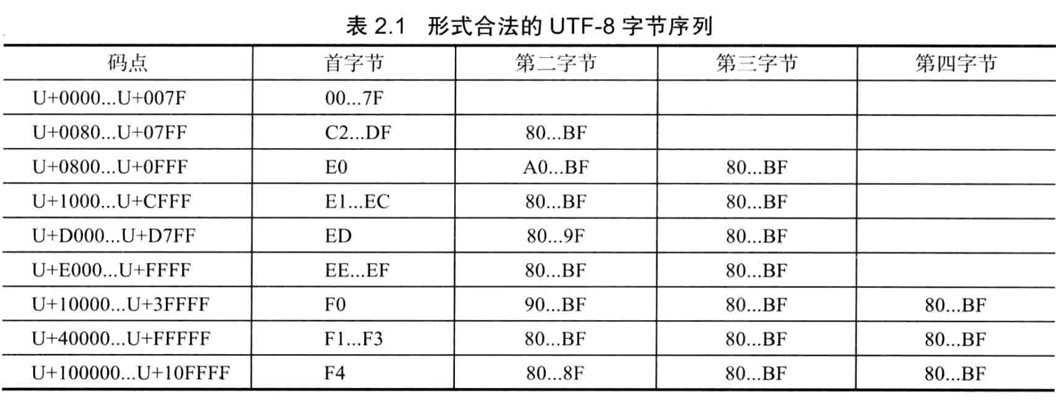
UTF-8编码 ★
UTF-8是一个多字节字符集,它可以表示在Unicode字符集中的每个字符,而且与美国7 位ASCII字符集向后兼容。每个UTF-8字符由1〜4个字节(请参阅表2.1)表示。
编码方式
如果某个字符仅由1个字节编码,那么此字节最高位是0且其他位包含码值(取值范围为0〜127)。
如果某个字符由多个字节的序列编码,那么首字节中前导1的位数与序列的总字节数相同,然后紧跟着一个0位,且后面的字节都被标记为一个前导“10”位模式。
在字节序列中的其余位拼接成Unicode的码点值(取值范围为0x80〜0x10FFFF)。
因此,
- 一个具有前导0位的字节是一个单字节码;
- 一个具有多个前导1位的字节是一个多字节序列的首字节;
- 一个具有前导“10”位模式的字节是一个多字节序列的延续字节。
这种字节格式允许检测每个序列的开始,而无须从字符串的开头解码。
UTF-8的安全问题
UTF-8的解码器有时会成为一个安全漏洞。在某些情况下,攻击者可以通过向它发送 UTF-8语法不允许的一个八位字节序列,来利用一个不谨慎的UTF-8解码器。
字符串大小与计数
计算字符串大小
保证字符串的存储空间具有容纳字符数据和空终结符的足够空间。数组和字符串的几个重要属性,对于正确分配空间,并防止缓冲区溢出是至关重要的。
- 大小(size):分配给数组的字节数(等于
sizeof(array))。 - 计数(count):在数组中的元素数目(等于在Visual Studio 2010中的
_countof(array))。 - 长度(length):在空终结符之前的字符数。
混淆这些概念经常会导致C和C++程序中的严重错误。
C标准保证类型为char的对象由单个字节组成。因此一个字符数组的大小等于一个char数组的计数(这也是数组的界限)。
而长度是在空终结符之前的字符数。对于一个正确地以null结尾的char类型的的字符串, 其长度必然是小于或等于其大小减1。
char str1[] = "123";
char *str2 = "123"; //两种定义字符串方式等价
printf("%d\n", sizeof(str1)); //4
printf("%d\n", strlen(str1)); //3
printf("%d\n", sizeof(str2)); //4
printf("%d\n", strlen(str2)); //3
char str1[10] = "123";
printf("%d\n", sizeof(str1)); //10
printf("%d\n", strlen(str1)); //3
宽字符串的大小
宽字符串被误认为是窄字符串或多字节字符串时,可能会不正确地计算其大小。c标准定义的wchar_t是一个整数类型,其值的范围可以代表所支持的语言环境中最大的扩展字符集的所有成员的不同编码。
Windows会使用UTF-16字符编码,所以wchar_t的大小通常为两个字节。
Linux和OSX(GCC/g++以及xcode中)使用UTF-32字符编码,所以 wchar_t的大小通常为4个字节。
在大多数平台上,wchar_t的大小至少是两个字节,因此, wchar_t数组的大小已不再等于对同一个数组的计数。
字符串计数安全问题案例
wchar_t wide_str1[] = L"0123456789";
wchar_t *wide_str2 = (wchar_t *)malloc(strlen(wide_str1) + 1);
if (wide_str2 == NULL) {
/*处理错误*/
}
/*...*/
free(wicle_str2);
wide_str2 = NULL;
上述代码有错误,经过测试:strlen(wide_str1)会报错,应该使用wcslen(wide_str1)。
wchar_t wide_str1[] = L"0123456789";
wchar_t *wide_str2 = (wchar_t *)malloc(wcslen(wide_str1) + 1);
if (wide_str2 == NULL) {
/*处理错误*/
}
/*...*/
free(wide_str2);
wide_str2 = NULL;
上述代码仍然有错误,因为wcslen(wide_str1)是字符串wide_str1中字符的个数10,而每个字符需要的内存空间是2字节,所以分配11字节是不够的,应该再乘以一个sizeof(wchar_t)。
wchar_t wide_str1[] = L"0123456789";
wchar_t *wjde_str2 = (wchar_t *)malloc((wcslen(wide_strl) + 1) * sizeof(wchar_t));
if (wide_str2 == NULL) {
/*处理错误*/
}
free(wide_str2);
wide_str2 = NULL;
字符串操作常见的4种错误 ★
在C和C++中,操作字符串很容易产生错误。最常见的错误有4种,分别是无界字符串复制(unbounded string copy)、差一错误(off-by-one error)、空结尾错误(null termination error)以及字符串截断(string truncation)。
1 无界字符串复制
无界字符串复制发生于从源数据复制数据到一个定长的字符数组时(例如,从标准输入 读取数据到一个定K的缓冲区中)。
include
include
void get_y_or_n(void) {
char response[8];puts(r'Continue? [y] n:");
gets(response);
if (response[0]=='n')exit(0);
}
如果在提示符下输入超过8个字符(包括空终结符),这个程序就会有不确定的行为。
gets()函数的主要问题是,它没有提供方法指定读入的字符数的限制,这种限制在此函数的实现中是显而易见的。
gets()源码分析:

实际上EOF的值通常为-1。
特殊的ASCII码
\r 是回车,return,前者使光标到行首
\n 是换行,newline,后者使光标下移一格
复制和连接字符串
复制和连接字符串时也容易出现错误,因为执行这个功能的许多标准库调用,如strcpy()、strcat()和sprintf()函数,执行无界复制操作。
当分配的空间不足以复制一个程序的输入(比如一个命令行参数)时,就会产生漏洞。虽然按照惯例,argv[0]包含程序名,但攻击者可以控制argv[0]的内容,在如下的程序中, 提供一个超过128个字节的字符串就会造成一个漏洞。而且,攻击者还可以把argv[0]设置为NULL来调用这个程序。
int main(int argc, char *argv[]) (
/*...*/
char prog_name[128];
strcpy(prog_name, argv[0]);
/*...*/
}
strlen()函数可用于确定由argv[0]到argv[argc-1]引用的字符串的长度,以便可动态分配足够的内存。记得要加一个字节以容纳用于终止字符串的空字符。请注意必须注意避免假设argv数组中的任何元素(包括argv[0])是非空的。
int main(int argc, char *argv[]) {
/* 不要假设argv[0]不许为空 */
const char * const name = argv[0] ? argv[0] : ' '; // 这一行写的什么鬼东西,完全运行不了啊(我猜大概意思是判断argv[]是否为空,不为空则把name指向它,为空则把name指向一个字符串' ')
char *prog_name = (char*)malloc(strlen(name) + 1);
if (prog_name != NULL) {
strcpy(prog_name, name);
}
else{
/* 动态分配内存失败,复原 */
}
}
2 差一错误
空字符结尾的字符串的另一个常见问题是差一错误(off-by-one error)。差一错误与无界 字符串复制有相似之处,即都涉及对数组的越界写问题,下列程序在微软Visual C++ 2010的 /W4警告级别上完全可以编译和链接,并且在Windows 7 上运行时也不报错,但它包含了几个差一错误。你能找出这个程序中所有的差一错误吗?

这些错误中,很多都是新手易犯的错误,但经验丰富的程序员也可能犯同样的错误,很容易开发出并部署类似于这个例子的程序,因为它在大多数系统上都可以顺利通过编译并且运行时也不报错。
3 空字符结尾错误
另一个常见的问题是字符串没有正确地以空字符结尾。一个字符串正确地以空字符结尾, 是指在数组最后一个元素处或在它之前存在一个空终结符。如果一个字符串没有以空字符结尾,程序可能会被欺骗,导致在数组边界之外读取或写入数据。
字符串必须在数组的最后一个元素的地址处或在它之前包含一个空终止字符,才可以安全地作为标准字符串处理函数如strcpy()函数或strlen()函数的参数被传递。空终止字符之所以是必要的,是因为前面这些函数以及其他由C标准定义的字符串处理函数,都依赖于它的存在来标记字符串的结尾。同样,如果程序对一个字符数组迭代循环的终止条件取决于为字符串分配的内存内是否存在一个空终止字符,字符串也必须以空字符结尾。
size_t i;
char ntbs[16];
/*...*/
for (i = 0; i < sizeof(ntbs); ++i) {
if (ntbs[i] = '\0') break;
/*...*/
}
int main(void) {
char a[16];
char b[16];
char c[16]:
strncpy(a,"0123456789abcdef",sizeof(a));
strncpy(b,"0123456789abcdef",sizeof(b));
strcpy(c, a);
/*...*/
}
在这个程序中,三个字符数组(a[]、b[]和c[])被声明为16个字节。虽然strncpy()到a仅限于写sizeof(a) (16个字节),的行为,导致结果字符串不是以空字符结尾的。
请注意,该规则并不排除使用字符数组。例如,即使在调用strncpy()之后,存储在ntbs字符数组中的字符串可能不是正确地以空字符结尾的,下面的程序片段也没有什么错。
char ntbs[NTBS_SIZE];
strncpy(ntbs, source, sizeof(ntbs)-1):
ntbs[sizeof(ntbs)-1] = '\0';
4 字符串截断
当目标字符数组的长度不足以容纳一个字符串的内容时,就会发生字符串截断。截断通常发生于读取用户输入或字符串复制时,通常是程序员试图防止缓冲区溢出的结果。尽管没有缓冲区溢出危害那么大,但字符串截断会丢失数据,有时也会导致软件漏洞。
与函数无关的字符串错误
大部分在标准字符串处理库
int main(int argc, char *argv[]){
int i = 0;
char buff[128];
char *arg1 = argv[];
if (argc == 0) {
puts("No arguments");
return EXIT_FAILURE;
}
while (arg1[i] != '\0') {
buff[i] = arg1[i];
i++;
}
buff[i] = '\0';
printf("buff = %s\n", buff);
exit(EXIT-SUCCESS);
}
当argv[]的长度大于128就会产生越界访问。