
5.1 服务器的分类
服务器按处理方式可以分为迭代服务器和并发服务器两类。前面章节介绍的服务器,每次只能处理一个客户的请求,它实现简单但效率很低,通常这种服务器被称为迭代服务器。然而在实际应用中,不可能让一个服务器长时间地为一个客户服务,而需要其具有同时处理多个客户请求的能力,这种同时可以处理多个客户请求的服务器称为并发服务器,其效率很高却实现复杂。在实际应用中,并发服务器应用的最广泛。本章将介绍实现并发服务器的两 种方式,它可以极大地提高服务器的处理能力和响应速度。迭代服务器和并发服务器的区别如图 5-1 和图 5-2 所示。
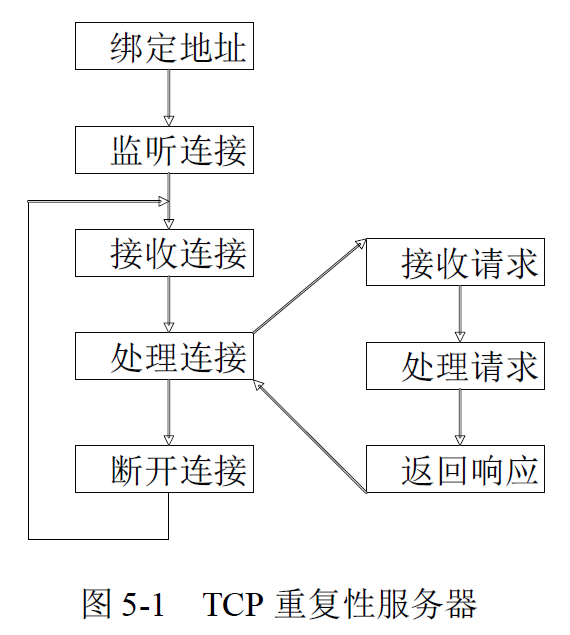
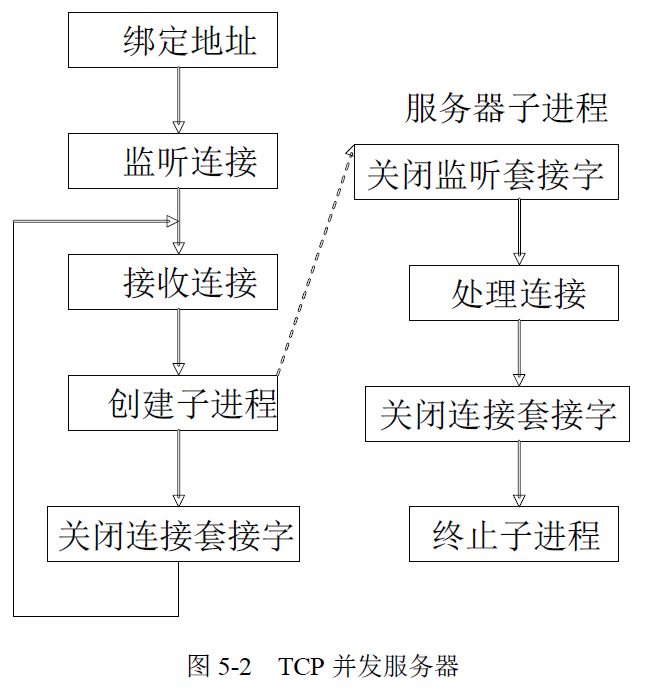
Linux 系统主要提供三种方式支持并发:进程、线程及I/O多路复用,本章主要讲述如何使用进程或线程实现并发服务器,I/O 多路复用技术将在后面的章节介绍。
5.2 多进程并发服务器
5.2.1 进程基础
进程是执行中的计算机程序,是在执行过程中不断变化的动态的实体。它拥有自己的地址空间、执行堆栈、文件描述符等。
Linux 系统中可以同时存在多个进程,它们互相独立又互相影响。
- 进程是独立的,在未经允许的情况下,一个进程不能访问另一个进程的资源,一个进程崩溃不会造成其他进程崩溃。
- 进程又是互相影响的,进程之间可以通过 IPC 机制相互通信。
每个进程都有一个非负整数作为惟一的进程ID,用来标识各个进程。在 Linux 系统中,多个进程可以同时执行相同的代码,从而支持并发技术。对于单 CPU 系统而言,CPU 一次只能执行一个进程,但操作系统可通过分时处理,使得各个进程分别在不同的时间段中执行,对于用户而言,这些进程是在同时执行。
5.2.2 进程创建
资源拷贝
可以通过调用 fork 和 vfork 函数来创建新进程。在创建新进程时,要进行资源拷贝。Linux 有三种资源拷贝的方式:
- 共享:新老进程共享通用的资源。当共享资源时,两个进程共同用一个数据结构,不需要为新进程另建。
- 直接拷贝:将父进程的文件、文件系统、虚拟内存等结构直接拷贝到子进程中。子进程创建后,父子进程拥有相同的结构。
- Copy on Write:拷贝虚拟内存页是相当困难和耗时的工作,所以能不拷贝就最好不要拷贝,如果必须拷贝,也要尽可能地少拷贝。为此,Linux采用了Copy on Write技术,把真正的虚拟内存拷贝推迟到两个进程中的任一个试图写虚拟页的时候。如果某虚拟内存页上没有出现写的动作,父子进程就一直共享该页而不用拷贝。
下面介绍创建新进程的两个函数 fork() 和 vfork() 。其中,fork 用于普通进程的创建,采用的是 Copy on Write 方式;而 vfork 使用完全共享的创建,新老进程共享同样的资源,完全没有拷贝。
fork函数
fork函数如下:
#include <unistd.h>
pid_t fork(void);
函数调用失败会返回 -1 。 fork 函数调用失败的原因主要有两个,系统中已经有太多的进程;该实际用户 ID 的进程总数超过了系统限制。
而如果调用成功,该函数调用一次会返回两次。在调用进程也就是父进程中,它返回一次,返回值是新派生的子进程的 ID 号,而在子进程中它还返回一次,返回值为 0 。 因此可以通过返回值来区别当前进程是子进程还是父进程。
为什么在 fork 的子进程中返回的是 0 ,而不是父进程 id 呢?原因在于:所有子进程都只有一个父进程,它可以通过调用 getppid 函数来得到父进程的 ID ,而对于父进程,它有很多个子进程,他没有办法通过一个函数得到各子进程的 ID 。如果父进程想跟踪所有子进程的 ID 它必须记住 fork 的返回值。
fork调用后,父进程和子进程继续执行 fork 函数后的指令,是父进程先执行还是子进程先执行是不确定的,这取决于系统内核所使用的调度算法。而父进程中调用 fork 之前打开的所有描述符在函数 fork 返回之后都是共享。如果父、子进程同时对同一个描述符进行操作,而且没有任何形式的同步,那么它们的输出就会相互混合。
fork 有两个典型的应用:
- 父、子进程各自执行不同的程序段,这是非常典型的网络服务器。父进程等待客户的服务请求。当这种请求到达时,父进程调用fork函数,产生一个子进程,由子进程对该请求作处理。父进程则继续等待下一个客户的服务请求。这种情况下,在fork函数之后,父、子进程需要关闭各自不使用的描述符。
- 每个进程要执行不同的程序。这种情况下,子进程在从fork函数返回后立即调用exec函数执行其他程序。
fork 函数的用法如下:
1. ……
2. pid_t pid;
3. if ((pid = fork()) > 0)
4. {
5. //parent process
6. }
7. else if(pid == 0)
8. {
9. //child process
10. exit(0);
11. }
12. else
13. {
14. printf("fork() error\n");
15. exit(0);
16. }
17. ……
第 3 行 产生子进程
第 4~6 行 父进程处理过程
第 7~11 行 子进程处理过程
第 10 行 子进程必须用 exit 函数退出
第 12~16 行 fork 函数调用失败处理
vfork函数
vfork 是完全共享的创建,新老进程共享同样的资源,完全没有拷贝。 当使用 vfork() 创建新进程时,父进程将被暂时阻塞,而子进程则可以借用父进程的地址空间运行。这个奇特状态将持续直到子进程要么退出,要么调用 execve(),至此父进程才继续执行。
vfork 函数如下:
#include <unistd.h>
pid_t vfork(void);
vfork 和 fork 函数一样,调用一次返回两次,父进程中它返回值是新派生的子进程的 ID 号,而在子进程中它返回值为 0 。如果函数调用失败将返回 -1 。
可以通过下面的程序来比较 fork 和 vfork 的不同:
1. #include <sys/types.h>
2. #include <unistd.h>
3. int main(void)
4. {
5. pid_t pid;
6. int status;
7. if ((pid = vfork()) == 0)
8. {
9. sleep(2);
10. printf("child running.\n");
11. printf("child sleeping.\n");
12. sleep(5);
13. printf("child dead.\n");
14. exit(0);
15. }
16. else if (pid > 0)
17. {
18. printf("parent running.\n");
19. printf("parent exit\n");
20. exit(0);
21. }
22. else
23. {
24. printf("fork error.\n");
25. exit(0);
26. }
27. }
第 7 行 产生子进程
第 8~15 行 子进程处理过程
第 16~21 行 父进程处理过程
第 22~26 行 vfork 函数调用失败处理
程序运行结果如下:
child running.
child sleeping.
child dead.
parent running.
parent exit
如果将 vfork 函数换成 fork 函数,该程序运行的结果如下:
parent running.
parent exit
[root@localhost test]# child running.
child sleeping.
child dead.
5.2.3 进程终止
进程终止的两种可能
进程终止存在两种可能:父进程先于子进程终止;子进程先于父进程终止。
- 如果父进程在子进程之前终止,则所有子进程的父进程被改为 init 进程,就是由 init 进程领养。在一个进程终止是,系统会逐个检查所有活动进程,判断这些进程是否是正要终止的进程的子进程。如果是,则该进程的父进程 ID 就更改为 1(init 的 ID)。这就保证了每个进程都有一个父进程。
- 如果子进程在父进程之前终止,系统内核会为每个终止子进程保存一些信息,这样父进程就可以通过调用 wait() 或 waitpid() 函数,获得子进程的终止信息。 终止子进程保存的信息包括进程 ID 、该进程的终止状态以及该进程使用的 CPU 时间总量。当父进程调用 wait() 或 waitpid() 函数时,系统内核可以释放终止进程所使用的所有存储 空间,关闭其所有打开文件。一个已经终止,但是其父进程尚未对其进行善后处理的进程称为僵尸进程。
当子进程正常或异常终止时,系统内核向其父进程发送 SIGCHLD 信号; 默认情况下,父进程忽略该信号,或者提供一个该信号发生时即被调用的函数。
wait函数
父进程可以通过调用 wait() 或 waitpid() 函数,获得子进程的终止信息。
wait 函数如下:
#include <sys/wait.h>
pid_t wait(int *statloc);
参数 statloc 返回子进程的终止状态(一个整数)。
当调用该函数时,如果有一个子进程已经终止,则该函数立即返回,并释放子进程所有资源 ,返回值是终止子进程的 ID 号。如果当前没有终止的子进程,但有正在执行的子进程,则 wait 将阻塞直到有子进程终止时才返回。如果当前既没有终止的子进程,也没有正在执行的子进程,则返回错误 -1 。
wait 函数的用法如下:
1. pid_t pid;
2. if((pid = fork()) > 0)
3. {
4. ……//parent process
5. int chdstatus;
6. wait(&chdstatus);
7. }
8. else if(pid == 0)
9. {
10. ……//child process
11. exit(0);
12. }
13. else
14. {
15. printf("fork() error\n");
16. exit(0);
17. }
waitpid函数
函数 waitpid 对等待哪个进程终止及是否采用阻塞操作方式方面给了更多的控制。
waipidt 函数如下:
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *statloc, int option);
当参数 pid 等于 1 而 option 等于 0 时,该函数等同于 wait() 函数。
参数 pid 指定了父进程要求知道哪些子进程的状态
- 当 pid 取 -1 时,要求知道任何一个子进程的终止状态。
- 当 pid 取值大于0 时,要求知道进程号为 pid 的子进程的终止状态。
- 当 pid 取值小于 -1 时,要求知道进程组号为 pid 的绝对值的子进程的终止状态。
参数 option 让用户指定附加选项。最常用的选项是WNO_HANG,它通知内核在没有已终止子进程时不要阻塞。
当前有终止的子进程时,返回值为子进程的 ID 号,同时参数 statloc 返回子进程的终止状态。否则返回值为 -1。
waitpid 函数的用法如下:
1. pid_t pid;
2. int stat;
3. while((pid = waitpid(-1, &stat, WNO_HANG)) > 0)
4. printf(“child %d terminated\n”, pid);
可以使用 while 循环调用 waitpid 函数,但是如果将 waitpid 函数换成 wait 函数,结果会怎么样?
exit函数
exit 函数是用来终止进程,返回状态的。
#include <stdlib.h>
void exit(int status);
本函数终止调用进程,关闭所有子进程打开的描述符,向父进程发送 SIGCHLD 信号,并返回状态,随后父进程就可通过调用 wait 或 waitpid 函数获得终止子进程的状态了。
5.2.4 多进程并发服务器
当父进程产生新的子进程后,父、子进程共享父进程在调用 fork 之前的所有描述符。一般情况下,接下来这样父进程只负责接收客户请求,而子进程只负责处理客户请求。关闭不需要的描述符既可以节省系统资源,又可以防止父、子进程同时对共享描述符进程操作,产生不可预计的后果。
此外,由于当 fork 函数返回后,与监听和已连接描述符相关联的文件表项的访问计数值均加1。当父进程调用 close 关闭已连接描述符时,只是将访问计数值减1。而描述符只在访问计数为 0 时才真正关闭。所以为了正确的关闭连接,当调用 fork 函数后父进程将不需要的已连接描述符关闭,而子进程关闭不需要的监听描述符。
下面用图例说明父进程调用fork 生成子进程后,父、子进程对描述符的操作过程。
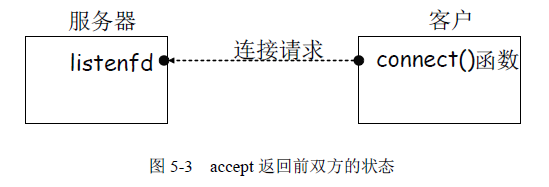
当服务器调用accept 函数时,连接请求从客户到达服务器时双方的状态如图5-3 所示。
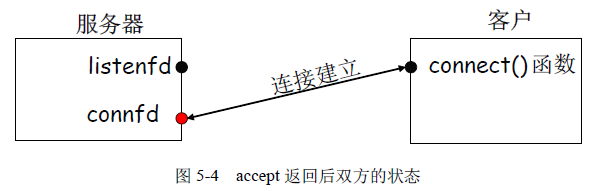
客户的连接请求被服务器接收后,新的已连接套接字即connfd 被创建,可通过此描述符读、写数据,此时双方的状态如图5-4 所示。
服务器的下一步就是调用fork 函数,如图5-5 所示,给出了从fork 函数返回后的状态。此时描述符listenfd 和connfd 在父、子进程间共享。
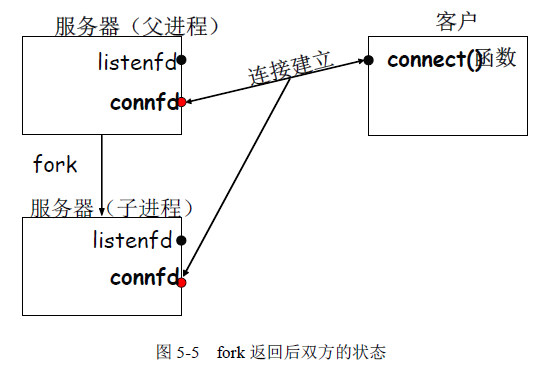
接下来就由父进程关闭已连接描述符,由子进程关闭监听描述符,当前双方的状态如图5-6 所示。
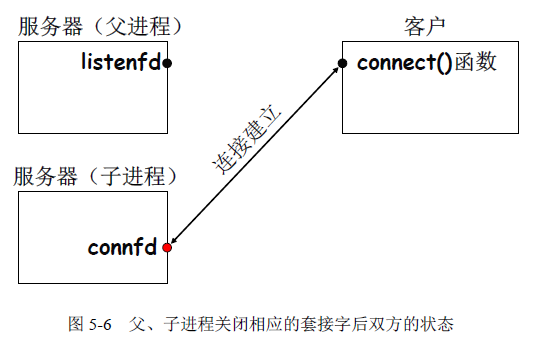
到此就是套接字的最终状态,子进程处理与客户的连接,父进程可以对监听描述符再次调用accept,继续处理下一个客户的连接请求。
5.2.5 多进程并发服务器实例★
下面是一个多进程并发服务器的实例,通过该实例可以了解多进程并发服务器是如何处理多客户的。
该实例包括服务器程序和客户程序,具体的功能如下:
- 服务器等待接收客户的连接请求,一旦连接成功则显示客户的地址,接着接收客户端的名称并显示。然后接收来自该客户的字符串,每当收到一个字符串,则显示该字符串,并将字符串按照恺撒密码的加密方式(K = 3)进行加密,再将加密后的字符发回客户端。之后,继续等待接收该客户的信息直到客户关闭连接。要求服务器具有同时处理多个客户请求的能力。
- 客户首先与相应的服务器建立连接。接着接收用户输入的客户端名称,并将其发送给服务器。然后继续接收用户输入的字符串,再将字符串发送给服务器,同时接收服务器发回的加密后的字符串并显示。之后,继续等待用户输入字符串,直至用户输入Ctrl+D,客户关闭连接并退出。
服务端程序
服务器源程序如下(程序 5-1):





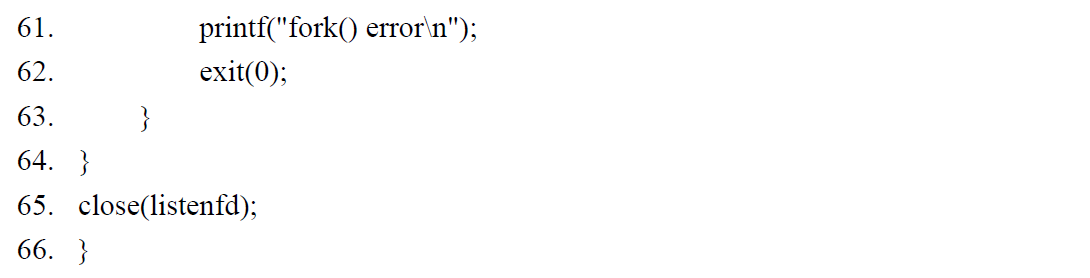



第 1~7 行:所需的头文件。
第 8~10 行:定义端口号、最大允许连接的数量及缓冲区的大小。
第 11 行:声明客户处理函数 process_cli(),用来处理客户的请求。
第 19~23 行:产生 TCP 套接字。
第 24~25 行:设置套接字选项为 SO_REUSEADDR 。
第 26~34 行:调用 bind 函数,将套接字绑定到相应的地址。本例中 IP 地址设为INADDR_ANY ,则可接收目的地址是本机任何 IP 地址的客户连接。
第 35~39 行:监听网络连接。
第 43~47 行:接受客户端的连接请求。
第 48~52 行:连接成功,产生子进程。父进程关闭已连接描述符,继续接受下一个客户的连接请求。
第 53~58 行:产生的子进程首先关闭监听描述符,然后调用 process_cli 函数处理与该客户的请求,函数返回时调用 exit 函数终止子进程。
第 59~63 行:如果子进程产生失败,显示出错信息并退出程序。
第 65 行:服务器退出时关闭监听描述符。
第 71 行:显示客户的 IP 地址,通过函数 inet_ntoa() 将客户地址转换程可显示的。
第 72~80 行:接收客户的名字并显示。
第 81~98 行:重复接收客户的数据,接收成功则显示,并将字符按恺撒密码的加密方式加密,然后将加密后的字符串发回给客户。
第 99 行:关闭已连接描述符。
客户端程序
对应的客户端程序如下(程序 5-2):





第 1~7 行:所需的头文件。
第 8~9 行:定义端口号和缓冲区的大小。这里的端口号要与服务器定义的一致。
第 10 行:声明 process() 函数,该函数用于连接后与服务器交互数据。
第 11 行: getMessage() 函数,用于提示并获得客户输入的字符串。
第 17~21 行:检查用户输入的格式。如果用户输 入不正确,提示用户正确的输入格式。
第 22~26 行:通过字符串形式的 IP 地址获得服务器的地址信息。
第 27~31 行:产生 TCP 套接字。
第 32~40 行:设置与之连接的服务器套接字地址结构,并连接到该服务器。
第 41 行:连接成功后,调用 process() 函数。
第 42 行:关闭套接字。
第 49~55 行:提示客户输入客户端的名称,并发送给服务器。如果用户输入 Ctrl+D ,则退出程序。
第 56 行:重复从标准输入获得用户输入的字符串直到用户输入 Ctrl+D 。
第 58 行:发送用户输入的字符串到服务器。
第 59~65 行: 接收并显示来自服务器的信息。如果接收的字节数是 0 ,表示服务器关闭了连接。
第 71~72 行:提示并获得用户从终端输入的字符串。
程序运行结果
首先运行服务器端程序。服务器端的运行结果如下:
./mthreadserver
You got a connection from 127.0.0.1.
Client's name is client.
Received client( client ) message: hello
You got a connection from 127.0.0.1.
Client's name is cuit.
Received client( client ) message: abc123
Received client( cuit ) message: welcom
Received client( cuit ) message: 123abc
Received client( client ) message: bye
Received client( cuit ) message: bye
客户 1 的运行结果如下:
Connected to server.
Input client's name : client
Input string to server:hello
Server Message: khoor
Input string to server:abc123
Server Message: def123
Input string to server:bye
Server Message: ebh
客户 2 的运行结果如下:
Connected to server.
Input client's name : cuit
Input string to server:welcom
Server Message: zhofrp
Input string to server:123abc
Server Message: 123def
Input string to server:bye
Server Message: ebh
从运行结果看,两个客户可以同时与服务器进行通信,与迭代服务器相比,在处理多个客户时性能有很大的提高。
5.3 多线程并发服务器
在 Linux 系统中,当一个进程需要另一个实体执行某件事时,该进程就使用 fork 派生一个新的子进程,让子进程去进行处理。 Linux 下的大部分网络服务程序都是这么编写的,在上面的多进程并发服务器实例中,可以看到,父进程负责接受连接请求、建立连接,然后派生子进程,由子进程处理与客户的交互。
虽然这种方式很多年来都使用的很好,但是使用fork 生成子进程存在的一些问题:
- 首先,fork 是昂贵的。内存映象要从父进程拷贝到子进程,所有描述符要在子进程中复制等等。虽然当前采用写时拷贝 copy on write 技术,将真正的拷贝推迟到子进程有写操作时,但 fork仍然是昂贵的。
- 其次, fork 子进程后,需要用进程间通信( IPC )在父子进程间传递信息。由于子进程从一开始就有父进程数据空间及所有描述符的拷贝,所以 fork 之前的信息容易传递。但是从子进程返回信息给父进程就需要作很多工作。
下面就介绍实现并发服务器的另外一种方式,使用多线程实现。多线程有助于解决以上两个问题。
5.3.1 线程基础
线程是进程内的独立执行实体和调度单元,又称为轻量级进程( lightwight process),创建线程比进程快 10~100 倍。一个进程内的所有线程共享相同的内存空间、全局变量等信息(这种机制又带来了同步问题),所以一个线程崩溃时,它会影响同一进程中的其他线程。
除了共享全局变量外, 它们还共享以下信息:
- 进程指令
- 大多数数据
- 打开的文件描述字
- 信号处理程序和信号处置
- 当前工作目录
- 用户ID和组ID
但每个线程有自己的私有信息:
- 线程ID
- 寄存器集合(包括程序计数器和栈指针)
- 栈(用于存放局部变量)
- error
- 信号掩码
- 优先级
5.3.2 线程基础函数
pthread_create 函数
pthread_create函数用于创建新线程。当一个程序开始运行时,系统产生一个称为初始线程或主线程的单个线程。额外的线程需要由 pthread_create 函数创建。
pthread_create函数如下:
#include <pthread.h>
int pthread_create(pthread_t *tid, const pthread_attr_t *attr, void *(*func)(void *), void *arg);
如果新线程创建成功,参数 tid 返回新生成的线程 ID 。一个进程中的每个线程都由一个线程 ID 标识,其类型为 pthread_t 。
attr 指向线程属性的指针。每个线程有很多属性包括:优先级、起始栈大小、是否是守护线程等等。通常将 attr 参数的值设为 NULL ,这时使用系统默认的属性。
但创建完一个新的线程后需要说明它将执行的函数。函数的地址由参数 func 指定。该函数必须是一个静态函数,它只有一个通用指针作为参数,并返回一个通用指针。该执行函数的调用参数是由 arg 指定, arg 是一个通用指针,用于往 func 函数中传递参数。如果需要传递多个参数时,必须将它们打包成一个结构,然后让 arg 指向该结构。线程以调用该执行函数开始。
如果函数调用成功返回 0 ,出错则返回非 0 。
pthread_create 函数的用法如下:
1. #include <pthread.h>
2. pthread_t tid;
3. int arg;
4. void *function(void *arg);
5. if (pthread_create(&tid, NULL, function, (void *)&arg))
6. {
7. //handle exception
8. exit(1);
9. }
10.……
第 1 行:所需头文件。
第 4 行:定义线程的执行函数。
第 5 行:生成新的线程, tid 返回新线程 ID ,新线程执行 function 函数,执行函数的参数为 arg 。
第 6~9 行:函数调用失败后的错误处理。
pthread_join 函数
pthread_join 函数与进程的 waitpid 函数功能类似,等待一个线程终止 。
pthread_join 函数如下:
#inlcude <pthread.h>
int pthread_join(pthread_t tid, void **status);
参数 tid 指定所等待的线程 ID。该函数必须指定要等待的线程,不能等待任一个线程结束。要求等待的线程必须是当前进程的成员,并且不是分离的线程或守护线程。几个线程不能同时等待一个线程完成,如果其中一个成功调用 pthread_join 函数,则其他线程将返回 ESRCH 错误。如果等待的线程已经终止,则该函数立即返回。如果参数 status 指针非空,则指向终止线程的退出状态值。
该函数如果调用成功则返回 0 ,出错时返回正的错误码。
pthread_detach 函数
线程分为两类:可联合的和分离的,默认情况下线程都是可联合的。
- 可联合的线程终止时,其线程 ID 和终止状态将保留,直到线程调用 pthread_join 函数。
- 而分离的线程退出后,系统将释放其所有资源,其他线程不能等待其终止。
如果一个线程需要知道另一个线程什么时候终止,最好保留第二个线程的可联合性。
pthread_detach 函数将指定的线程变成分离的。
pthread_detach 函数如下:
#inlcude <pthread.h>
int pthread_detach(pthread_t tid);
参数 tid 指定要设置为分离的线程 ID 。
如果函数调用成功返回0 ,否则返回错误码。
pthread_self 函数
每一个线程都有一个ID,pthread_self 函数返回自己的线程 ID。
pthread_self 函数如下:
#inlcude <pthread.h>
pthread_t pthread_self(void);
函数返回调用函数的线程 ID 。
线程可以通过如下语句,将自己设为可分离的:
pthread_detach(pthread_self());
pthread_exit 函数
函数 pthread_exit 用于终止当前线程,并返回状态值,如果当前线程是可联合的,则其退出状态将保留。
pthread_exit 函数如下:
#include <pthread.h>
void pthread_exit(void *status);
参数 status 指向函数的退出状态。这里的 status 不能指向一个局部变量,因为当前线程终止后,其所有局部变量将被撤销。
该函数没有返回值。
还有两种方法可以使线程终止:
- 启动线程的函数pthread_create的第三个参数返回。该返回值就是线程的终止状态。
- 如果进程的main函数返回或者任何线程调用了exit函数,进程将终止,线程将随之终止。
5.3.3 给新线程传递参数
线程产生函数 pthread_create ,只能传递一个参数给线程的执行函数。所以当需要传递多个数据时,需要将所有数据封装在一个结构中,再将该结构传递给执行函数。
传递的方式如下:


第 1 行:声明新线程的执行函数。
第 2~5 行:定义结构体 ARG 。
第 14~17 行:接受客户的连接请求。
第 18 行:设置线程执行函数的参数。
第 19~22 行:产生线程。
第 28~29 行:取出相应的参数。
第 30 行:处理客户请求。
第 31 行:关闭已连接描述符。
第 32 行:退出线程。
以上传递参数的方法存在问题, 处理 一个客户 请求时,其 可以 正常 工作,但 同时处理 多个客户 时, 则 无法正常工作 。 其原因在于,传递给执行参数的参数是以指针 形式传递的。所以变量 arg 是所有线程共用的。如果新线程 A 正在处理客户 A 的请求时,主线程又接受了另一客户 B 的连接,那么主线程将修改 arg 中的内容。这时,线程 A 再从 arg 中获得的信息实际上是客户 B 的信息。问题的关键就在于如何使每个新线程在主线程修改 arg 之前获得一份 arg 的拷贝,而不是共用 arg 。
可以通过为 arg 分配空间来解决这个问题。首先为每个新线程分配存储 arg 的空间,再将 arg 传递给新线程,新线程使用后释放分配的 arg 空间。
例子如下:


第 1 行:声明线程的执行函数。
第 2~5 行:定义结构体 ARG 。
第 15~ 18 行:接受客户的连接请求。
第 19~20 行:为参数分配空间并设置参数值。
第 21 行:产生线程。
第 28~29 行:取出相应的参数。
第 30 行:处理客户请求。
第 31 行:关闭已连接描述符。
第 32 行:释放为该线程分配的 arg 空间。
第 33 行:退出线程。
5.3.4 多线程并发服务器实例★
下面介绍一个使用多线程实现并发服务器的实例。通过该实例可了解多线程并发服务器是如何处理多客户请求的。
该实例同样分为服务器和客户两个部分,服务器端程序如下,客户程序与多进程并发服务器实例中的客户程序相同。完成的功能与多进程并发服务器实例 相同。
服务端程序
服务器源程序如下:




第 1~8 行:所需的头文件。
第 9~11 行:定义端口号、最大允许连接的数量及缓冲区的大小。
第 12 行:声明客户处理函数 process_cli() cli(),用来处理客户的请求。
第 13 行:声明线程执行函数。
第 14~17 行:定义 ARG 结构。用于主线程向新线程传递参数。
第 26~30 行:产生 TCP 套接字。
第 31~32 行:设置套接字选项为 SO_REUSEADDR 。
第 33~41 行:调用 bind 函数,将套接字绑定到相应的地址。本例中 IP 地址设为INADDR_ANY ,则可接 收目的地址是本机任何 IP 地址的客户连接。
第 42~46 行:监听网络连接。
第 47~65 行:主线程接受客户端的连接请求。当连接建立后,生成新的线程与该客户端进行通信。主线程继续接受下一个客户连接。
第 55~57 行:分配空间给 arg ,然后把已连接描述符和客户地址信息赋给 arg 。
第 58~62 行:产生新线程,如果新线程产生失败,显示出错信息并退出程序。
第 64 行:服务器退出时关闭监听描述符。
第 66~99 行:处理客户的请求。
第 70 行:显示客户的 IP 地址,通过函数 inet_ntoa() 将客户地址转换程可显示的。
第 71~79 行:接收客户的名字并显示。
第 80~97 行:重复接收客户的数据,接收成功则显示,并将字符按恺撒密码的加密方式加密,然后将加密后的字符串发回给客户。
第 98 行:关闭已连接描述符。
第100~107 行:实现线程的执行函数 function 。
第 104 行:调用 process_cli() 函数。
第 105 行:释放分配给该线程的 arg 空间。
第 106 行:退出线程。
客户端程序
客户端程序
客户程序与多进程并发服务器实例中的客户程序相同。
程序运行结果
首先运行服务器端程序:
服务器端的运行结果如下:
You got a connection from 127.0.0.1.
Client's name is client.
Received client( client ) message: hello
Received client( client ) message: 123abc
You got a connection from 127.0.0.1.
Client's name is cuit.
Received client( cuit ) message: welcom
Received client( cuit ) message: xyz890
Received client( client ) message: zoom
Received client( client ) message: bye
Received client( cuit ) message: bye bye
客户 1 的运行结果如下:
Connected to server.
Input client's name: client
Input string to server: hello
Server Message: khoor
Input string to server: 123abc
Server Message: 123def
Input string to server: zoom
Server Message: crrp
Input string to server: bye
Server Message: ebh
客户 2 的运行结果如下:
Connected to server.
Input client's name : cuit
Input string to server: welcom
Server Message: zhofrp
Input string to server: xyz890
Server Message: abc890
Input string to server: bye bye
Server Message: ebh ebh
5.3.5 线程安全函数▽
由于一个进程中所有线程共享相同的内存空间,如果多个线程修改相同的内存区就会造成意想不到的后果。这就是线程安全问题,在多线程环境中应十分小心使用共享变量。
在 Linux 系统中,由于静态变量的使用, 造成许多 函数 是线程 不 安全的 。 下面 通过例子说明线程安全性问题。该例子实现的功能与多线程并发服务器实例类似,但增加了一个对客户发送的所有数据进行存储的功能,服务器将每个连接的用户所发来的所有数据存储起来,当连接终止后,服务器将显示客户的名字及相应的所有数据。
……
从上面的例子可以看出,在多线程环境里,应避免使用静态变量。在Linux 系统中提供了线程特定数据( TSD )来取代静态变量。它类似于全局变量 但是,是 各个线程私有的,它以线程为界限 。 TSD 是定义线程私有数据的 惟一 方法。同一进程中的所有线程,它们的同一特定数据项都由一个进程内惟一的 关键字 KEY 来标志。用这个关键字,线程可以存取线程私有数据。
……
5.3.6 线程安全实例▽
下面的例子就是使用 TSD 取代静态变量后,实现与上例相同的功能。
……
5.3.7 用函数参变量实现线程安全性▽
还可以使用另外一种方法实现线程的安全函数,就是通过使用函数的参变量来代替静态变量。这种方法非常简单,但是需要改变函数的原型,增加相应的参变量。而且该函数的调用函数必须为这些变量分配空间并进行初始化。
下面的例子与使用 TSD 具有相同的功能,也能保证服务器的正常工作。
……